
1. 머신 러닝이란(Machine Learning)
기계가 스스로 학습해 가는 프로그래밍
1. 학습단계 : 함수 /$ y(x) $/ 학습 데이터에 기반해 결정하는 단계
2. 시험셋 : 모델을 평가하기 위해서 사용하는 새로운 데이터
3. 일반화 : 모델에서 학습에 사용된 데이터가 아닌 이전에 접하지 못한 새로운 데이터에 대해올바른 예측을 수행하는 역량
4. 지도학습 : target이 주어진 경우
4-1. 분류(classification) : 이미지 분류와 같은 경우 타겟값이 정해진경우
4-2.회기(regression) : 타겟값이 세분화 되있는 경우
5. 비지도 학습 : target이 없는 경우
5-1. 군집 (clustering) : 비슷한 데이터 끼리 모아서 클러스터함
2. 다항식 곡선 근사 (ploynomial curve fitting)
학습데이터 : 입력 백터 $ X= (x_1 , ... , x_N)^T , t = (t_1, ... , t_N)^T $
목표 : 새로운 입력백터 \hat{x} 가 주어졌을 때 목표값 \hat {t}를 예측하는 것
확률이론(probabillty theory): 예측값의 불확실성을 정량화 시켜 표현할 수 있는 수학적인 프레임워크르 제공한다.
결정이론(decision theory) : 확률적 표현을 바탕으로 최적의 예측을 수행할 수있는 방법론을 제공한다
식 : $ y(x,W) = w_0 + w_1x + w_2x^2 + \cdots + w_Mx^M = \sum^M_{j=0}w_jx^j $
3.오차함수
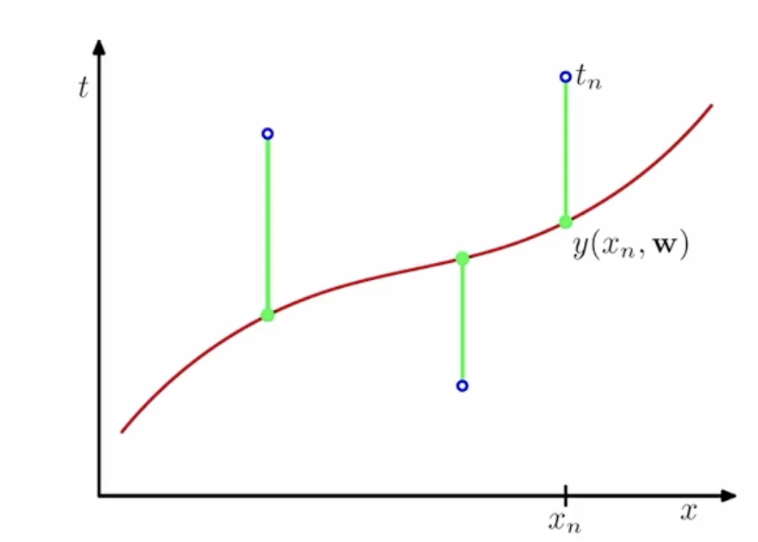
데이터들과의 만든 곡선의 거리를 제는것
$ E(W) \frac{1}{2} \sum^N _{n=1}\{y(x_n , w) -t_n\}^2 $
4. 과소 적합(Under-fitting) 과대적합(Over-fitting)
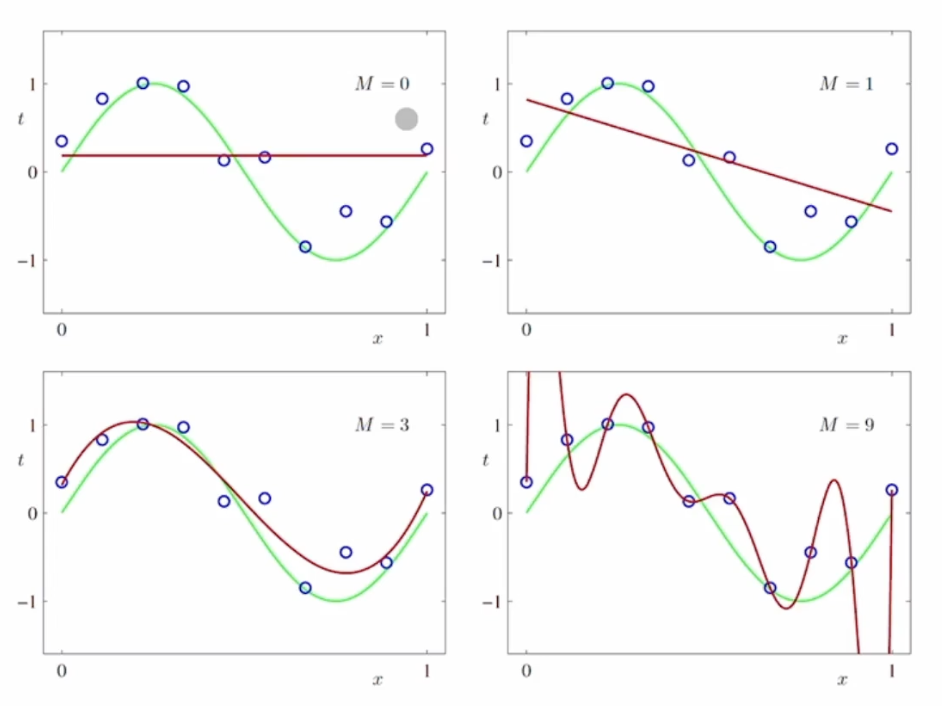
몇번 휘어지는가
기울기를 몇변 변형하냐에 따라 모델링의 적합도가 달라진다
$ E_{RMS} = \sqrt{2E(w*)/N} $
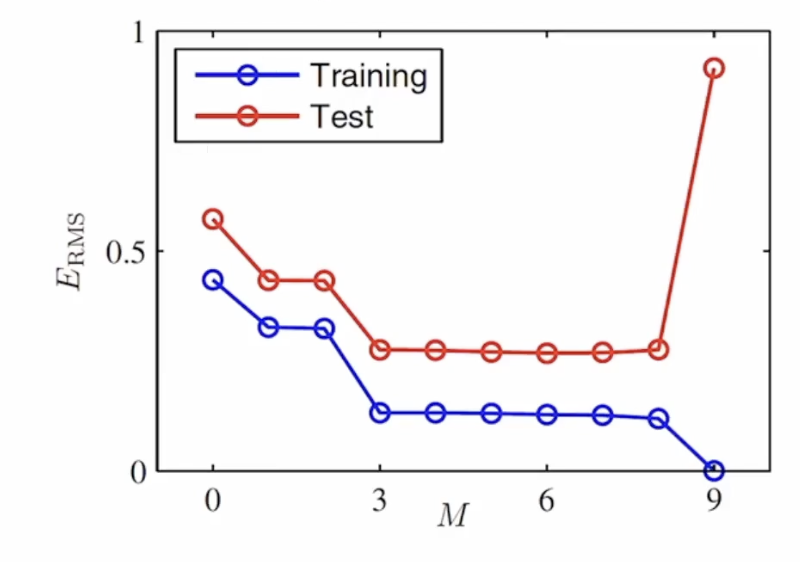
위와같이 기울기(굴곡)가 몇개나 있나에 따라서 실제 데이터는 잘 맞는데
테스트하기위해 넣은 데이터는 많이 틀리는 결과를 볼수 있다
5. 데이터의 양과 모델 그래프의 모습
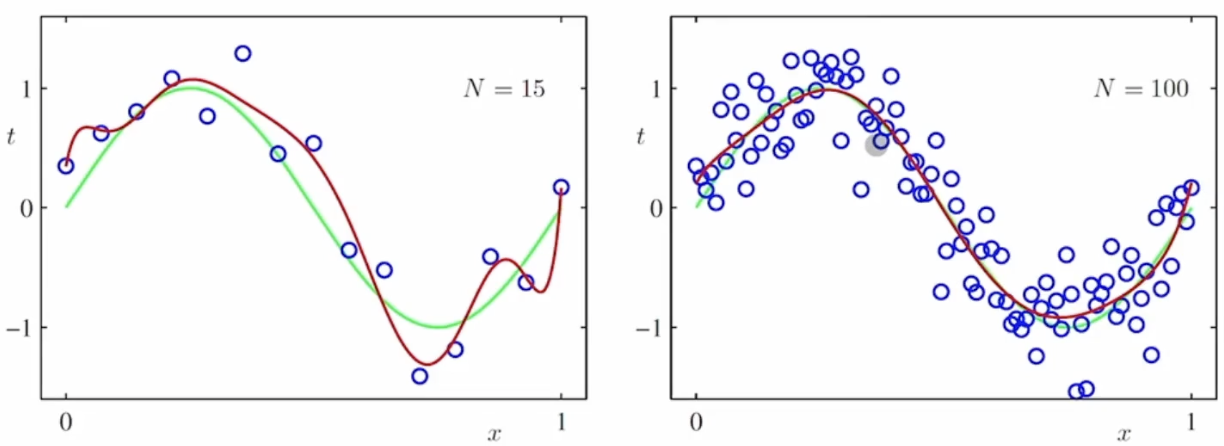
이와같이 데이터가 많으면 굴곡을 적절하게 만들어준다
6. 규제화

굴곡이 얼마나 많나에 따라서 기울기의 숫자 정보이다 너무 위로가거나 너무 아래로 간다면 과대접합일 경우가 높다
그럼 얼마나 굴곡이 있어야 적당할까
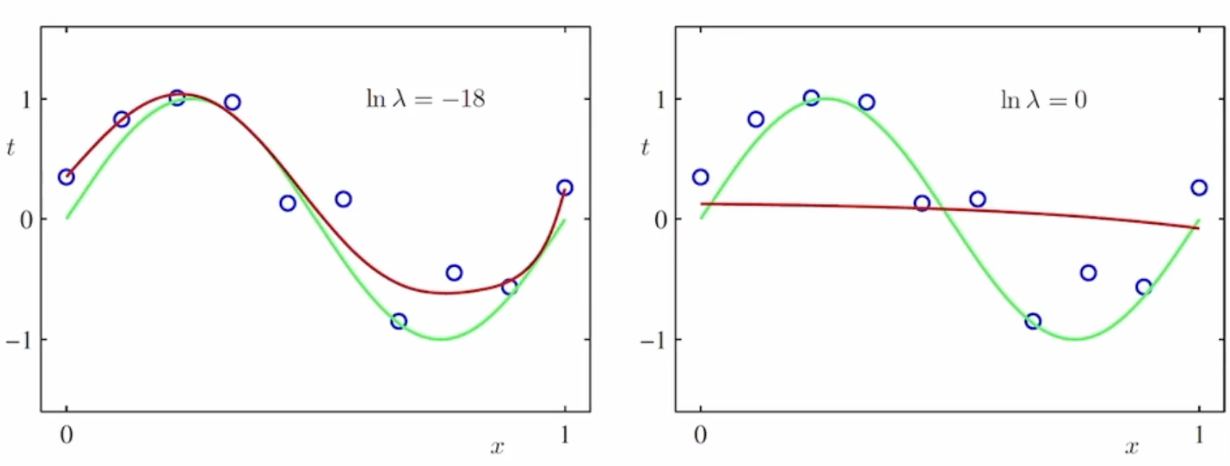
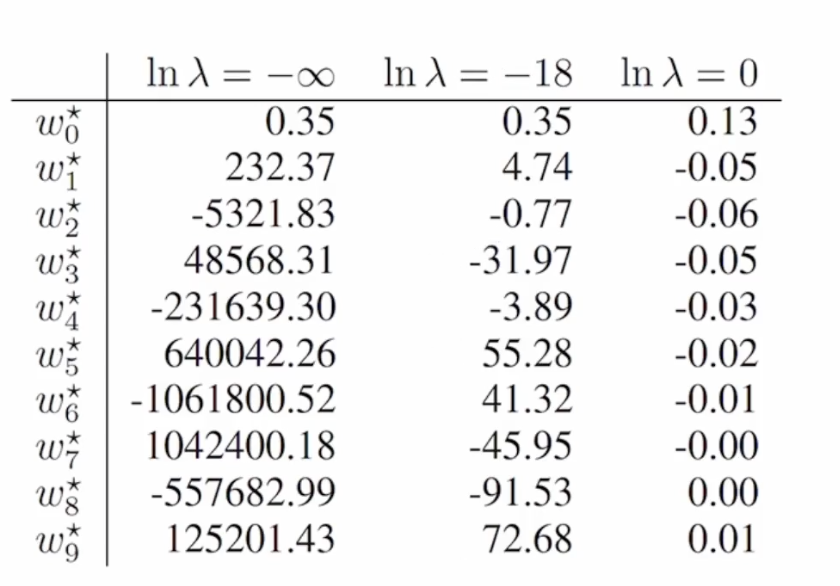
$ \tilde{E}(w) = \frac{1}{2}\sum^N_{n=1} \{y(x_n, w)-t_n\}^2 +\frac{\lambda }{2} \left \| w \right \|^2 $
$ \left \| w \right \|^2 = w^Tw = w^2_0 +w^2_1 + \cdot + w^2_M $
이식의 $ \lambda $ 를 보자 람다가 변화할수록 곡선과의 대이터의 거리가 멀어지고 짧아질수가 있다
람다가 커지면 거질수록 곡선과의 거리를 작게 만드는 것을 이해하면된다!
너무 무한대면 과대접합된거처럼 또 된다 왜나면 딱 맞추려고 하기 때문이다
'Programmers > 데브코스 인공지능' 카테고리의 다른 글
| [프로그래머스 스쿨 AI] Weak6 결정이론 (0) | 2021.06.01 |
|---|---|
| [프로그래머스 스쿨 AI] Weak 6 확률이론 (0) | 2021.05.28 |
| [프로그래머스 스쿨 AI] Weak 5 Django + uwsgi+ nginx + aws 완전 삭제후 따라해보기 드뎌! 배포 됫다 (0) | 2021.05.21 |
| [프로그래머스 스쿨 AI] Weak 5 Django DB, forms (0) | 2021.05.19 |
| [프로그래머스 스쿨 AI] Weak 5 django (0) | 2021.05.17 |